
ML and AI Blogs | Issue# 16 [April 27, 2025]
Introduction
In today’s digital landscape, misinformation spreads at unprecedented speeds. The ease with which false information can propagate through social media platforms, news aggregators, and messaging apps has created an urgent need for effective fact-checking solutions. To address this challenge, we have developed AskVeracity – an AI-powered misinformation detection and fact-checking application designed to verify recent news and factual claims by gathering and analyzing evidence from multiple sources in real time.
This blog post will walk through the architecture, implementation, and effectiveness of the AskVeracity system, providing insights into how modern AI techniques can be applied to combat misinformation.
Project Overview
AskVeracity is a fact-checking and misinformation detection system that analyzes claims to determine their truthfulness through evidence gathering and analysis. Built with a focus on transparency and reliability, the application aims to support broader efforts in countering misinformation.
Key Features
- Multi-source Evidence Retrieval: Gathers evidence from Wikipedia, Wikidata, news articles, academic sources, fact-checking sites, and domain-specific RSS feeds.
- Category-aware Prioritization: Detects claim categories (AI, science, politics, world events, etc.) and prioritizes relevant sources.
- Transparent Classification: Clearly explains verdicts with confidence scores and supporting evidence.
- Safety-first Approach: Prioritizes avoiding false assertions when evidence is insufficient.
- User-friendly Interface: Streamlit-based web interface with evidence exploration options.
Technical Stack
- Frameworks: LangGraph for agent orchestration and Streamlit for web interface.
- NLP Processing: spaCy for entity recognition and claim analysis.
- Large Language Model (LLM): OpenAI GPT-3.5 Turbo for claim extraction, classification, and explanation.
- Evidence Sources: Wikipedia API, Wikidata SPARQL, News API, OpenAlex, Google Fact Check Tools API, and RSS feeds.
- Deployment: Hugging Face Spaces for web hosting (Free tier; CPU basic; 2 vCPUs with 16GB RAM).
System Architecture
AskVeracity follows an agentic architecture based on the ReAct (Reasoning + Acting) framework. The system is built around a central agent that orchestrates individual tools to perform the fact-checking process.
Core Components
- Agent System: A LangGraph-based ReAct agent that coordinates the entire fact-checking process.
- Claim Extraction: Extracts the main factual claim from user input.
- Category Detection: Identifies the claim category for targeted evidence retrieval.
- Evidence Retrieval: Gathers and analyzes relevant evidence from multiple sources.
- Truth Classification: Evaluates evidence to determine claim truthfulness with confidence scores.
- Explanation Generation: Creates human-readable explanations of verdicts.
- Web Interface: Streamlit-based User Interface (UI) for input and result display.
The following diagram illustrates the system architecture.
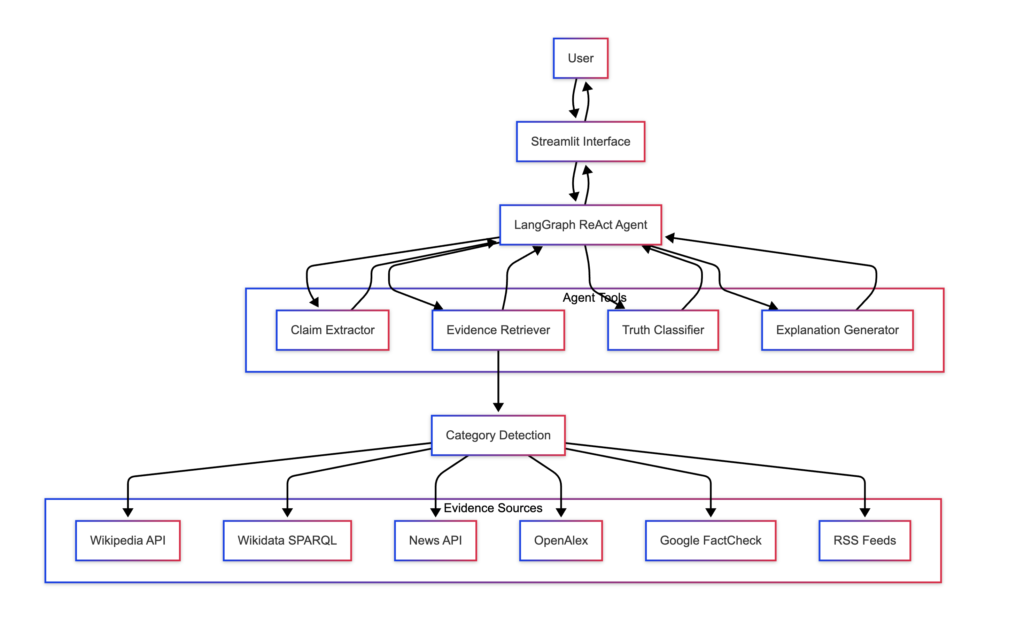
Data Flow
The verification process follows a clear sequence given below.
- User submits a claim through the Streamlit interface.
- The agent extracts the main factual claim.
- The system detects the claim category.
- Evidence is gathered from multiple sources based on category.
- Each evidence item is classified as supporting, contradicting, or insufficient.
- The system aggregates evidence classifications to determine the overall verdict.
- A human-readable explanation is generated.
- Results are presented to the user with evidence details.
Performance Optimizations
AskVeracity implements several key optimizations to maintain responsiveness and efficiency.
- Smart Model Caching: The system caches LLM and Natural Language Processing (NLP) models after initial loading using a custom decorator-based approach, significantly reducing API calls and latency for subsequent verifications. See cached_model() and get_llm_model() in models.py for the implementation.
- Streamlit Caching: The application leverages Streamlit’s built-in caching mechanisms (
@st.cache_resource) to persist loaded models and agent instances across multiple user sessions, dramatically reducing startup time for subsequent users accessing the application. See get_agent() in app.py for the implementation. - Parallel Evidence Retrieval: Evidence gathering from multiple sources happens concurrently using ThreadPoolExecutor, reducing total processing time compared to sequential retrieval. The implementation is available in the function
retrieve_combined_evidence() in evidence_retrieval.py. See the Category Detection and Evidence Retrieval subsection under the section Implementation Deep Dive for more. - Early Relevance Analysis: The system performs relevance scoring during the retrieval process rather than after collecting all evidence, allowing prioritization of the most relevant sources. The implementation can be found in the function
analyze_evidence_relevance - Category-aware Source Prioritization: See subsection Category Detection and Evidence Retrieval under section Implementation Deep Dive for more.
- Memory Optimization: The system implements several memory management techniques to ensure efficient operation in constrained environments like Hugging Face Spaces. See format_response() in agent.py for the code.
- Resource Cleanup: The system implements cleanup handlers registered with
atexitto ensure proper resource release on application termination, preventing memory leaks during deployment. The relevant code can be found in the function cleanup_resources() in app.py.
The code for the implementation of smart model caching, memory optimization, and resource cleanup is provided below. The aforementioned optimizations work together to ensure the system remains responsive despite the complexity of gathering and analyzing evidence from multiple sources.
# Add caching decorator
def cached_model(func):
"""
Decorator to cache model loading for improved performance.
This decorator ensures that models are only loaded once and
then reused for subsequent calls, improving performance by
avoiding redundant model loading.
...
"""
cache = {}
@functools.wraps(func)
def wrapper(*args, **kwargs):
# Use function name as cache key
key = func.__name__
if key not in cache:
logger.info(f"Model not in cache, calling {key}...")
cache[key] = func(*args, **kwargs)
return cache[key]
return wrapper
@cached_model
def get_llm_model():
"""
Get the ChatOpenAI model, initializing if needed.
...
"""
global model
if model is None:
try:
# Try to load just the LLM model if not loaded yet
logger.info("Initializing ChatOpenAI model...")
model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
logger.info("Initialized ChatOpenAI model")
except Exception as e:
logger.error(f"Error initializing ChatOpenAI model: {str(e)}")
# Fall back to full initialization
initialize_models()
return model```
# Memory management - limit the size of evidence and thoughts
# To keep memory usage reasonable for web deployment
if "evidence" in result and isinstance(result["evidence"], list):
limited_evidence = []
for ev in result["evidence"]:
if isinstance(ev, str) and len(ev) > 500:
limited_evidence.append(ev[:497] + "...")
else:
limited_evidence.append(ev)
result["evidence"] = limited_evidence
# Limit thoughts to conserve memory
if "thoughts" in result and len(result["thoughts"]) > 10:
result["thoughts"] = result["thoughts"][:10]def cleanup_resources():
"""
Clean up resources when app is closed.
...
"""
try:
# Clear any cached data
st.cache_data.clear()
# Reset performance tracker
performance_tracker.reset()
# Log cleanup
logger.info("Resources cleaned up successfully")
except Exception as e:
logger.error(f"Error during cleanup: {e}")
# Register cleanup handler
atexit.register(cleanup_resources)Implementation Deep Dive
Let us go ahead and review the implememtation details of AskVeracity.
The Agent System
The agent system is built using LangGraph’s ReAct framework, which combines reasoning and acting capabilities. The agent coordinates four main tools to perform fact-checking shown below. See agent.py for complete code of the four tools.
# Define LangGraph Tools
@tool
def claim_extractor(query):
"""
Tool that extracts factual claims from a given text.
...
"""
performance_tracker.log_claim_processed()
return extract_claims(query)
@tool
def evidence_retriever(query):
"""
Tool that retrieves evidence from multiple sources for a claim.
...
"""
return retrieve_combined_evidence(query)
@tool
def truth_classifier(query, evidence):
"""
Tool that classifies the truthfulness of a claim based on evidence.
...
"""
classification_results = classify_with_llm(query, evidence)
truth_label, confidence = aggregate_evidence(classification_results)
...
# Return a structured dictionary with all needed information
result = {
"verdict": truth_label,
"confidence": confidence,
"results": classification_results
}
return json.dumps(result)
@tool
def explanation_generator(claim, evidence_results, truth_label):
"""
Tool that generates a human-readable explanation for the verdict.
...
"""
...
return generate_explanation(claim, evidence_results, truth_label)The agent is initialized with a specific prompt that guides its reasoning process. Shown below, this structured prompt ensures that the agent follows a consistent verification process without unnecessary steps. Find complete code here.
prompt = PromptTemplate(
input_variables=["input", "tool_names"],
template=f"""
You are a fact-checking assistant that verifies claims by gathering evidence and
determining their truthfulness. Follow these exact steps in sequence:
1. Call claim_extractor to extract the main factual claim
2. Call evidence_retriever to gather evidence about the claim
3. Call truth_classifier to evaluate the claim using the evidence
4. Call explanation_generator to explain the result
5. Provide your Final Answer that summarizes everything
Execute these steps in order without unnecessary thinking steps between tool calls.
Be direct and efficient in your verification process.
{FORMAT_INSTRUCTIONS_TEMPLATE}
"""
)Claim Extraction
The claim extraction module identifies the main factual assertion from the user’s input. For concise inputs (under 30 words), the system preserves the original text. For longer inputs, it uses an LLM to extract the core claim. See claim_extraction.py for complete code of the extract_claims() function shown below.
def extract_claims(text):
"""
Extract the main factual claim from the provided text.
For concise claims (<30 words), preserves them exactly.
For longer text, uses OpenAI to extract the claim.
"""
...
if len(text.split()) < 30:
...
return text
...
# For longer text, use OpenAI for extraction
extracted_claim = extract_with_openai(text)
...
return extracted_claim
...The extraction process includes validation to ensure that the LLM does not add information not present in the original text. This validation ensures that the system does not introduce bias or additional information. The system also implements specialized location entity validation to ensure geographic accuracy. When extracting claims, AskVeracity checks that no location information is inappropriately added or modified. The function validate_extraction() shown below incorporates this functionality and the complete code is available here.
```
def validate_extraction(original_text, extracted_claim, nlp):
"""
Validate that the extracted claim doesn't add information not present in the original text
"""
...
# Check for added location information
location_terms = ["united states", "america", "u.s.", "usa", "china", "india", "europe",
"russia", "japan", "uk", "germany", "france", "australia"]
for term in location_terms:
if term in extracted_claim.lower() and term not in original_text.lower():
logger.warning(f"Extraction added location '{term}' not in original, using original text")
return original_text
...
# Check for entity preservation using spaCy
extracted_doc = nlp(extracted_claim)
extracted_entities = [ent.text.lower() for ent in extracted_doc.ents]
original_doc = nlp(original_text)
original_entities = [ent.text.lower() for ent in original_doc.ents]
# Check for new entities that don't exist in original
for entity in extracted_entities:
if not any(entity in orig_entity or orig_entity in entity for orig_entity in original_entities):
...
return original_text
return extracted_claim
...Category Detection and Evidence Retrieval
A critical feature in AskVeracity is its category-aware evidence retrieval system. The system detects the category of a claim to prioritize relevant sources. AskVeracity supports categories including AI, science, technology, politics, business, world events, sports, and entertainment, each with dedicated category-based source prioritization. The category detection mechanism is reflected in the detect_claim_category() function in category_detection.py.
def detect_claim_category(claim: str) -> Tuple[str, float]:
"""
Detect the most likely category of a claim and its confidence score
...
"""
if not claim:
return "general", 0.3
# Lowercase for better matching
claim_lower = claim.lower()
# Count matches for each category
category_scores = {}
for category, keywords in CLAIM_CATEGORIES.items():
# Count how many keywords from this category appear in the claim
matches = sum(1 for keyword in keywords if keyword.lower() in claim_lower)
# Calculate a simple score based on matches
if matches > 0:
# Calculate a more significant score based on number of matches
score = min(0.9, 0.3 + (matches * 0.1)) # Base 0.3 + 0.1 per match, max 0.9
category_scores[category] = score
# Find category with highest score
if not category_scores:
return "general", 0.3
top_category = max(category_scores.items(), key=lambda x: x[1])
category_name, confidence = top_category
# If the top score is too low, return general
if confidence < 0.3:
return "general", 0.3
return category_name, confidenceThe evidence retrieval system gathers information from multiple sources in parallel as shown below. See evidence_retrieval.py for complete code of the retrieve_combined_evidence() function.
def retrieve_combined_evidence(claim):
"""
Retrieve evidence from multiple sources in parallel and analyze relevance.
...
"""
logger.info(f"Starting evidence retrieval for: {claim}")
start_time = time.time()
...
# Extract key claim components for relevance matching
claim_components = extract_claim_components(claim)
...
# Determine if claim has temporal attributes
requires_recent_evidence = bool(claim_components.get("temporal_words", []))
...
# Determine the claim category
category, confidence = detect_claim_category(claim)
...
# Define evidence sources to query in parallel
evidence_sources = [
("wikipedia", retrieve_evidence_from_wikipedia, [claim]),
("wikidata", retrieve_evidence_from_wikidata, [claim]),
("scholarly", retrieve_evidence_from_openalex, [claim]),
("claimreview", retrieve_evidence_from_factcheck, [claim]),
("news", retrieve_news_articles, [claim, requires_recent_evidence])
]
# Add category-specific RSS feeds
if category == "ai":
category_feeds = get_category_specific_rss_feeds(category)
evidence_sources.append(("rss_ai", retrieve_evidence_from_rss, [claim, 10, category_feeds]))
# Add technology fallback feeds for AI
fallback_category = get_fallback_category(category)
if fallback_category:
fallback_feeds = get_category_specific_rss_feeds(fallback_category)
evidence_sources.append(("rss_tech", retrieve_evidence_from_rss, [claim, 10, fallback_feeds]))
else:
# For other categories, add their specific RSS feeds
category_feeds = get_category_specific_rss_feeds(category)
if category_feeds:
evidence_sources.append(("rss_category", retrieve_evidence_from_rss, [claim, 10, category_feeds]))
# Add default RSS feeds as fallback for all non-AI categories
evidence_sources.append(("rss_default", retrieve_evidence_from_rss, [claim, 10]))
# Execute all evidence gathering in parallel
with ThreadPoolExecutor(max_workers=len(evidence_sources)) as executor:
# Create a mapping of futures to source names for easier tracking
futures = {}
for source_name, func, args in evidence_sources:
future = executor.submit(func, *args)
futures[future] = source_name
# Process results as they complete
for future in as_completed(futures):
source_name = futures[future]
try:
evidence_items = future.result()
if evidence_items:
all_evidence.extend(evidence_items)
source_counts[source_name] = len(evidence_items)
logger.info(f"Retrieved {len(evidence_items)} items from {source_name}")
except Exception as e:
logger.error(f"Error retrieving from {source_name}: {str(e)}")
...The combined evidence is then scored for relevance using entity and verb matching. The analyze_evidence_relevance() shown below implements this functionality and is defined in evidence_retrieval.py. This relevance scoring ensures that only the most pertinent evidence is used for classification. The evidence retrieval system shortlists 10 evidence items (if available) with the highest relevance scores and passes them to the LLM for classification.
def analyze_evidence_relevance(evidence_items, claim_components):
"""
Analyze evidence relevance based on entity match, verb match and keyword match.
...
"""
if not evidence_items or not claim_components:
return []
scored_evidence = []
# Extract components for easier access
claim_entities = claim_components.get("entities", [])
claim_verbs = claim_components.get("verbs", [])
claim_keywords = claim_components.get("keywords", [])
for evidence in evidence_items:
if not isinstance(evidence, str):
continue
evidence_lower = evidence.lower()
# 1. Count entity matches - try both case-sensitive and case-insensitive matching
entity_matches = 0
for entity in claim_entities:
# Try exact match first (preserves case)
if entity in evidence:
entity_matches += 1
# Then try lowercase match
elif entity.lower() in evidence_lower:
entity_matches += 1
# 2. Count verb matches (always lowercase)
verb_matches = sum(1 for verb in claim_verbs if verb in evidence_lower)
# 3. Calculate entity and verb weighted score
entity_verb_score = (entity_matches * 3.0) + (verb_matches * 2.0)
# 4. Count keyword matches (always lowercase)
keyword_matches = sum(1 for keyword in claim_keywords if keyword in evidence_lower)
# 5. Determine final score based on entity and verb matches
if entity_verb_score > 0:
final_score = entity_verb_score
else:
final_score = keyword_matches * 1.0 # Use keyword matches if no entity/verb matches
scored_evidence.append((evidence, final_score))
# Sort by score (descending)
scored_evidence.sort(key=lambda x: x[1], reverse=True)
return scored_evidenceClassification System
The classification system makes use of the LLM to evaluate each of the 10 evidence items (if available) against the claim, determining if it supports, contradicts, or is insufficient to verify the claim. The system uses a precise regex pattern to extract structured classification results from the LLM output, ensuring consistent parsing of analysis results even with potential variations in formatting or whitespace. See classify_with_llm() in classification.py for complete code and functionality of the classification system.
def classify_with_llm(query, evidence):
"""
Classification function that evaluates evidence against a claim
to determine support, contradiction, or insufficient evidence.
...
"""
...
# Get the LLM model
llm_model = get_llm_model()
...
# Extract claim components for improved keyword detection
claim_components = extract_claim_keywords(query)
essential_keywords = claim_components.get("keywords", [])
essential_entities = claim_components.get("entities", [])
...
# Create a structured prompt with explicit format instructions
prompt = f"""
CLAIM: {query}
EVIDENCE:
{evidence_text}
TASK: Evaluate if each evidence supports, contradicts, or is insufficient/irrelevant to the claim.
INSTRUCTIONS:
1. For each evidence, provide your analysis in EXACTLY this format:
EVIDENCE [number] ANALYSIS:
Classification: [Choose exactly one: support/contradict/insufficient]
Confidence: [number between 0-100]
Reason: [brief explanation]
2. Support = Evidence EXPLICITLY confirms ALL parts of the claim are true
3. Contradict = Evidence EXPLICITLY confirms the claim is false
4. Insufficient = Evidence is irrelevant, ambiguous, or doesn't provide enough information
...
FOCUS ON THE EXACT CLAIM ONLY.
ESSENTIAL KEYWORDS TO LOOK FOR: {', '.join(essential_keywords)}
ESSENTIAL ENTITIES TO VERIFY: {', '.join(essential_entities)}
...
"""
# Get response
result = llm_model.invoke(prompt, temperature=0)
result_text = result.content.strip()
...
# Extract classification results with regex
analysis_pattern = r'EVIDENCE\s+(\d+)\s+ANALYSIS:[\s\n]*Classification:[\s\n]*(support|contradict|insufficient)[\s\n]*Confidence:[\s\n]*(\d+)[\s\n]*Reason:[\s\n]*(.*?)(?=[\s\n]*EVIDENCE\s+\d+\s+ANALYSIS:|[\s\n]*$)'
matches = list(re.finditer(analysis_pattern, result_text, re.IGNORECASE | re.DOTALL))
# Process matches into structured results
classification_results = []
...
for match in matches:
evidence_idx = int(match.group(1)) - 1
classification = match.group(2).lower()
confidence = int(match.group(3)) / 100.0 # Convert to 0-1 scale
reason = match.group(4).strip()
if 0 <= evidence_idx < len(evidence):
evidence_text = evidence[evidence_idx]
...
# Create result entry
classification_results.append({
"label": classification,
"confidence": confidence,
"evidence": evidence_text,
"reason": reason
})
...
return classification_resultsThe individual evidence classifications are then aggregated to determine the overall verdict using the aggregate_evidence() function shown below. This weighted approach considers both the quantity and quality of evidence, resulting in a more nuanced verdict. See classification.py for more.
def aggregate_evidence(classification_results):
"""
Aggregate evidence classifications to determine overall verdict
using a weighted scoring system of evidence count and quality.
...
"""
...
# Only consider support and contradict evidence items
support_items = [item for item in classification_results if item.get("label") == "support"]
contradict_items = [item for item in classification_results if item.get("label") == "contradict"]
# Count number of support and contradict items
support_count = len(support_items)
contradict_count = len(contradict_items)
# Calculate confidence scores for support and contradict items
support_confidence_sum = sum(item.get("confidence", 0) for item in support_items)
contradict_confidence_sum = sum(item.get("confidence", 0) for item in contradict_items)
# Apply weights: 55% for count, 45% for quality (confidence)
# Normalize counts to avoid division by zero
max_count = max(1, max(support_count, contradict_count))
# Calculate weighted scores
count_support_score = (support_count / max_count) * 0.55
count_contradict_score = (contradict_count / max_count) * 0.55
# Normalize confidence scores to avoid division by zero
max_confidence_sum = max(1, max(support_confidence_sum, contradict_confidence_sum))
quality_support_score = (support_confidence_sum / max_confidence_sum) * 0.45
quality_contradict_score = (contradict_confidence_sum / max_confidence_sum) * 0.45
# Total scores
total_support = count_support_score + quality_support_score
total_contradict = count_contradict_score + quality_contradict_score
# Check if all evidence is irrelevant/insufficient
if support_count == 0 and contradict_count == 0:
...
return "Uncertain", 0.0
# Determine verdict based on higher total score
if total_support > total_contradict:
verdict = "True (Based on Evidence)"
min_score = total_contradict
max_score = total_support
else:
verdict = "False (Based on Evidence)"
min_score = total_support
max_score = total_contradict
# Calculate final confidence using the formula:
# (1 - min_score/max_score) * 100%
if max_score > 0:
final_confidence = 1.0 - (min_score / max_score)
else:
final_confidence = 0.0
...
return verdict, final_confidenceAdditionally, the system implements robust fallback mechanisms when evidence classification is incomplete. This ensures that even if the agent’s workflow is disrupted, the system will still attempt to classify claims with available evidence, enhancing result reliability. The code snippet below from the function format_response() in agent.py illustrates this functionality.
```
# IMPORTANT: ENHANCED FALLBACK MECHANISM
# Always run truth classification if evidence was collected but classifier wasn't called
if found_tools["evidence_retriever"] and not found_tools["truth_classifier"]:
logger.info("Truth classifier was not called by the agent, executing fallback classification")
try:
...
# Get the evidence from the results
evidence = result["evidence"]
claim = result["claim"] or "Unknown claim"
# Force classification even with minimal evidence
if evidence:
# Classify with available evidence
classification_results = classify_with_llm(claim, evidence)
truth_label, confidence = aggregate_evidence(classification_results)
# Update result with classification results
result["classification"] = truth_label
result["confidence"] = confidence
result["classification_results"] = classification_results
...
except Exception as e:
logger.error(f"Error in fallback truth classification: {e}")Safety-First Approach
A key innovation in AskVeracity is the "safety-first" approach to classification. This approach prioritizes avoiding false assertions over making definitive judgments, making the system more reliable and resilient. See classification.py for more.
```
# In aggregate_evidence() function:
# Check if all evidence is irrelevant/insufficient
if support_count == 0 and contradict_count == 0: ...
return "Uncertain", 0.0 # Default with zero confidence
...
# When confidence is very low
if final_confidence < 0.1: # Less than 10%
# Keep the verdict but with very low confidence
logger.info(f"Very low confidence verdict: {verdict} with {final_confidence:.2f} confidence")
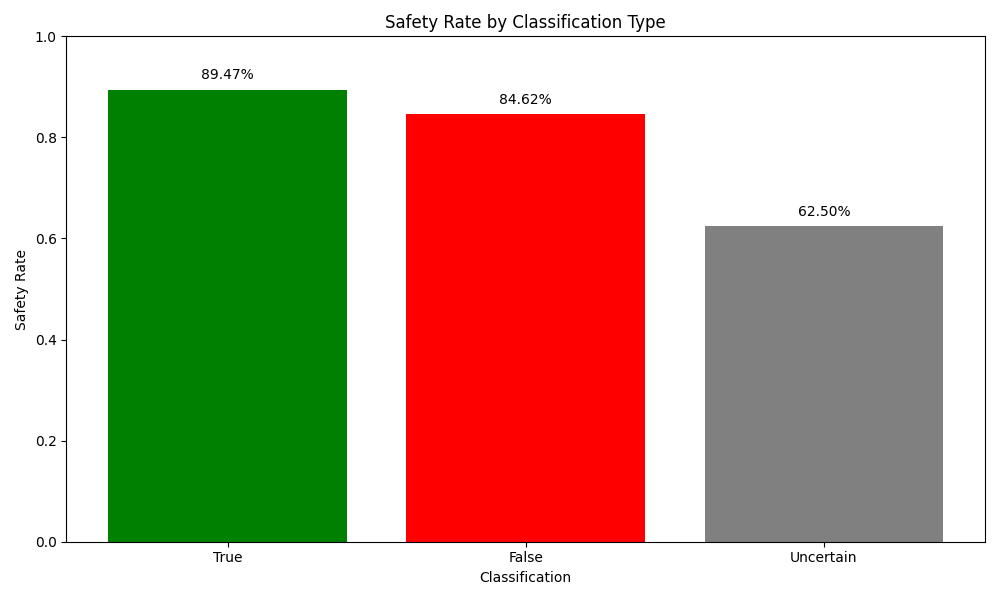
...This safety-first approach is reflected in the “safety rate” metric, which measures how often the system avoids making incorrect assertions. A high safety rate (averaging 83.3% across test runs in this case, see section Performance Evaluation for more) indicates that even when the system cannot correctly classify a claim, it tends to abstain from judgment rather than spread misinformation. Precisely, the high safety rate indicates the system is high reliability.
Explanation Generation
The explanation generator creates human-readable explanations of the verdict, tailored to the confidence level. It tailors its language based on the verdict and confidence level, providing transparent reasoning behind the system’s conclusions. The explanation generation functionality is implemented by generate_explanation() in explanation.py.
Special attention is given to very low confidence verdicts (below 10%), where the system generates explanations that emphasize uncertainty and strongly recommend verification from other authoritative sources.
def generate_explanation(claim, evidence_results, truth_label, confidence=None):
"""
Generate an explanation for the claim's classification based on evidence.
...
"""
...
# Normalize truth_label
normalized_label = normalize_truth_label(truth_label)
...
# Get the LLM model
explanation_model = get_llm_model()
# Extract most relevant evidence
most_relevant_evidence = extract_most_relevant_evidence(evidence_results)
... ...
Claim: "{claim}"
Verdict: {normalized_label} (with {confidence_desc})
Available Evidence:
{evidence_text}
Task: Generate a clear explanation that:
1. States that the claim appears to be true based on the available evidence
2. EMPHASIZES that the confidence level is VERY LOW
3. Explains that this means the evidence slightly favors the claim but is not strong enough to be certain
4. STRONGLY recommends that the user verify this with other authoritative sources
5. Is factual and precise
"""
else:
prompt = f"""
Task: Generate a clear explanation that:
1. Clearly states that the claim IS TRUE based on the evidence
2. {"Pay special attention to the logical relationship since the claim contains negation" if has_negation else "Explains why the evidence supports the claim"}
3. Uses confidence level of {confidence_desc}
4. Highlights the most relevant supporting evidence
5. Is factual and precise
"""
elif "false" in normalized_label.lower():
# Similar prompts for false verdicts...
...
else:
prompt = f"""
Task: Generate a clear explanation that:
1. Clearly states that there is insufficient evidence to determine if the claim is true or false
2. Explains what information is missing or why the available evidence is insufficient
3. Uses confidence level of {confidence_desc}
4. Makes NO speculation about whether the claim might be true or false
5. Explicitly mentions that the user should seek information from other reliable sources
"""
... ...
...Additionally, the system ensures that explanations are always generated even if the agent workflow fails to call the explanation generator. The relevant code from the function format_response() in agent.py is provided below.
```
# ENHANCED: Always generate explanation if classification exists but explanation wasn't called
if (found_tools["truth_classifier"] or result["classification"] != "Uncertain") and not found_tools["explanation_generator"]:
logger.info("Explanation generator was not called by the agent, using fallback explanation generation")
try:
# Get the necessary inputs for explanation generation
claim = result["claim"] or "Unknown claim"
evidence = result["evidence"]
truth_label = result["classification"]
confidence_value = result["confidence"]
classification_results = result.get("classification_results", [])
# Choose the best available evidence for explanation
explanation_evidence = classification_results if classification_results else evidence
# Force explanation generation even with minimal evidence
explanation = generate_explanation(claim, explanation_evidence, truth_label, confidence_value)
# Use the generated explanation
if explanation:
...Web interface
AskVeracity’s web interface is built with Streamlit, offering an intuitive and accessible user experience. See app.py for complete code.
# Main interface
st.markdown("### Enter a claim to verify")
...
"Justin Trudeau is not the Canadian Prime Minister anymore. "
"A recent piece of news. "
),
key="claim_input_area",
on_change=on_input_change,
label_visibility="collapsed",
max_chars=None,
disabled=st.session_state.processing)
# Add information about claim formatting
st.info("""
**Tip for more accurate results:**
- As older news tends to get deprioritized by sources, trying recent news may yield better results
- Try news claims as they appear in the sources
- For claims older than 36 hours, consider rephrasing the claim by removing time-sensitive words like "recently"
- Rephrase verbs from present tense to past tense for older events
... ...
)
... # Display results
analysis_container = st.container()
with analysis_container:
... ... ... ... ...The interface includes tabs for exploring evidence, with separate sections for supporting and contradicting evidence. This interface design prioritizes transparency, allowing users to easily explore the evidence and understand how the system reached its conclusion.
# Evidence presentation
evidence_tabs = st.tabs(["Supporting Evidence", "Contradicting Evidence", "Source Details"])
# Supporting Evidence tab
with evidence_tabs[0]:
if support_evidence:
for i, res in enumerate(support_evidence):
evidence_text = res.get("evidence", "")
confidence = res.get("confidence", 0)
reason = res.get("reason", "No reason provided")
...
...Performance Evaluation
AskVeracity has been rigorously tested with a set of 40 test claims spanning three classes: True, False, and Uncertain. Note that claims across all of the categories (AI, science, technology, politics, business, world events, sports, and entertainment) were tested. The evaluation reveals important insights about the system’s effectiveness. See evaluate_performance.py for the complete implementation of performance evaluation.
The system tracks comprehensive performance metrics including claims processed count, evidence retrieval success rates, processing times, confidence scores, source types distribution, and temporal relevance. We use these metrics to evaluate the system’s performance using accuracy, safety rate, processing time, and confidence scores.
Overall Performance Metrics
Across three evaluation runs, AskVeracity demonstrates:
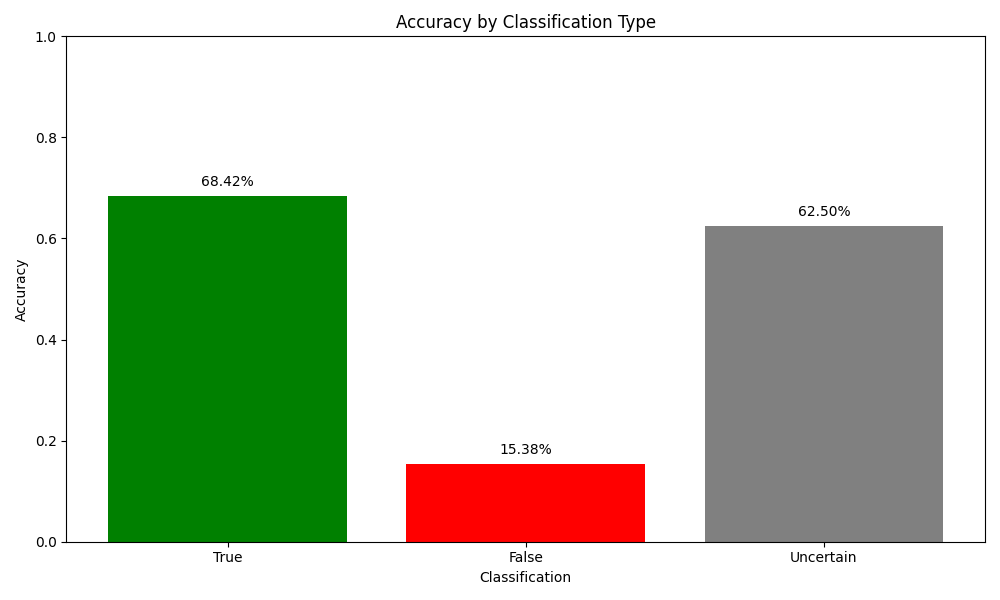
- Accuracy: Between 50.0% and 57.5% (average: 53.3%).
- Safety Rate: Between 82.5% and 85.0% (average: 83.3%).
- Average Processing Time: Between 28.13 and 37.10 seconds per claim.
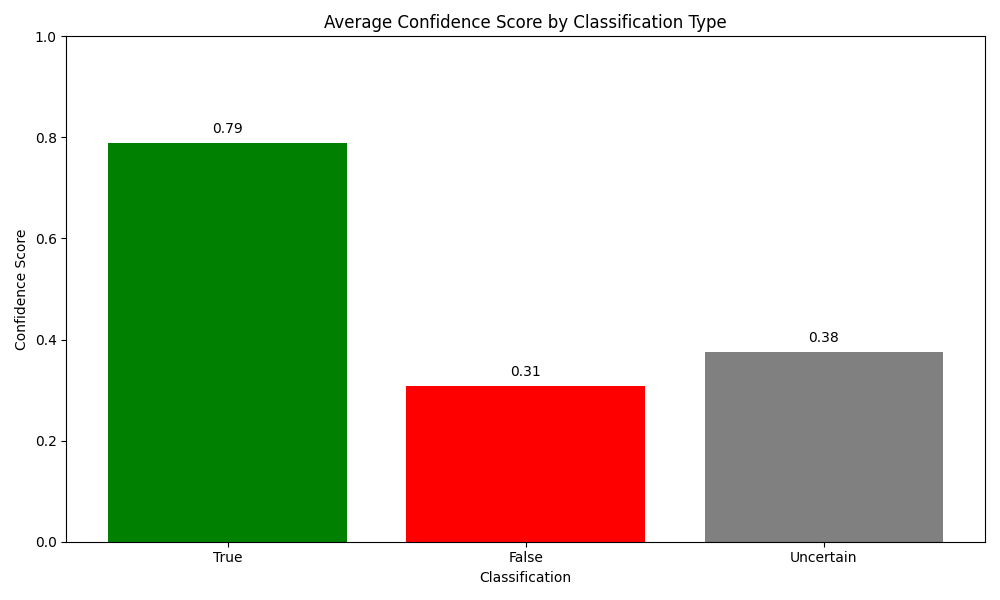
- Average Confidence Score: Between 0.55 and 0.60.
The safety rate is a particularly important metric, measuring how often the system avoids making incorrect assertions. It counts both correct classifications and cases where the system abstains from judgment (classifies as Uncertain) rather than making an incorrect assertion. The figure below indicates the results from the best run out of the three.

Per-Class Performance
The performance varies significantly across claim types of all of the eight categories. More below.
True Claims (19 test claims)
- Accuracy: 68.4-73.7% (average: 70.2%)
- Safety Rate: 84.2-89.5% (average: 87.7%)
- Confidence: 0.79-0.84 (average: 0.82)
False Claims (13 test claims)
- Accuracy: 15.4-30.8% (average: 23.1%)
- Safety Rate: 84.6-92.3% (average: 88.5%)
- Confidence: 0.31-0.38 (average: 0.33)
Uncertain Claims (8 test claims)
- Accuracy: 62.5% (consistent)
- Safety Rate: 62.5% (consistent)
- Confidence: 0.31-0.38 (average: 0.36)
The three figures below show the accuracy, safety rate, and average confidence scores for claims across all categories for the best of the three test runs. These metrics reveal that the system performs better at identifying true claims and often classifies false claims as Uncertain rather than incorrectly labeling them as true. This cautious approach contributes to the high safety rate, which is desirable for a fact-checking system where avoiding the spread of misinformation is a priority.
Performance Analysis
Several patterns emerge from the evaluation:
- Higher accuracy for true claims: The system more reliably identifies true statements, possibly because evidence supporting true claims tends to be more explicit and readily available.
- Conservative approach to false claims: The system frequently classifies false claims as Uncertain rather than False when evidence is limited, contributing to the lower accuracy but higher safety rate (enhancing system reliability) for false claims.
- Temporal sensitivity: Claims about very recent events may receive Uncertain verdicts due to limited available evidence, even if they are factually true or false.
- Confidence correlation: The system’s confidence scores correlate well with accuracy – true claims receive higher confidence scores (0.79-0.84) than false (0.31-0.38) or uncertain claims (0.31-0.38).
The variance in performance metrics across different evaluation runs highlights the dynamic nature of evidence availability based on news sources, especially for recent, evolving, and challenging topics. This variability is an inherent characteristic of real-time fact-checking systems that rely on current information. This also highlights the massive amount of information we deal with on a daily basis, to the point that even the most important recent news feels old within a day.
Challenges and Solutions
We will review some of the main challenges faced while designing and developing AskVeracity and the approach used to solve them.
Evidence Availability
Challenge: Evidence for claims can be inconsistent, especially for very recent events or niche topics.
Solution: AskVeracity implements category-specific evidence gathering with fallback mechanisms. For example, AI claims fall back to technology sources if AI-specific sources yield insufficient evidence. All other categories fall back to a default list of RSS feeds spread across all of the categories. See evidence_retrieval.py for more.
...Temporal Sensitivity
Challenge: News sources quickly deprioritize older stories, making evidence for time-sensitive claims difficult to find after a few days.
Solution:
- Implemented temporal word detection to identify time-sensitive claims.
- Adjusted evidence retrieval windows based on temporal indicators.
- Provided guidance to users about rephrasing claims with appropriate verb tenses.
The aforementioned temporal word detection functionality can be found in the get_recent_date_range() function (shown below) in evidence_retrieval.py.
def get_recent_date_range(claim=None):
"""
Return date range for news filtering based on temporal indicators in the claim.
...
"""
today = datetime.now()
# Default to 3 days for no claim or claims without temporal indicators
default_days = 3
extended_days = 15 # For 'recently', 'this week', etc.
if claim:
# Specific day indicators get 3 days
specific_day_terms = ["today", "yesterday", "day before yesterday"]
# Extended time terms get 15 days
extended_time_terms = [
"recently", "currently", "freshly", "this week", "few days",
"couple of days", "last week", "past week", "several days", "anymore"
]
claim_lower = claim.lower()
# Check for extended time terms first, then specific day terms
if any(term in claim_lower for term in extended_time_terms):
from_date = (today - timedelta(days=extended_days)).strftime('%Y-%m-%d')
to_date = today.strftime('%Y-%m-%d')
... ...Classification Accuracy
Challenge: Claims can be complex, with parts that are true and parts that are false, making binary classification challenging.
Solution:
- Implemented a thorough LLM prompt that focuses on exact claim verification.
- Used entity and verb matching to assess evidence relevance.
- Added fallback classification when evidence is ambiguous.
- Implemented tense normalization to handle verb form variations.
The tense normalization mechanism shown below can be found in the normalize_tense
def normalize_tense(claim):
"""
Normalize verb tenses in claims to ensure consistent classification.
...
"""
# Define patterns to normalize common verb forms.
tense_patterns = [
# Present simple to past tense conversions
(r'\bunveils\b', r'unveiled'),
(r'\blaunches\b', r'launched'),
(r'\breleases\b', r'released'),
# ... more patterns
# Perfect forms (has/have/had + past participle) to simple past
(r'\b(has|have|had)\s+unveiled\b', r'unveiled'),
(r'\b(has|have|had)\s+launched\b', r'launched'),
# ... more patterns
]
# Apply normalization patterns
normalized = claim
for pattern, replacement in tense_patterns:
normalized = re.sub(pattern, replacement, normalized, flags=re.IGNORECASE)
...UI and Experience
The AskVeracity UI is designed to be intuitive and informative, providing users with both the verdict and the evidence supporting it. The complete UI of AskVeracity is defined in the file app.py. More on the top features and functionalities of the UI below.
Key Interface Features
The Streamlit-based interface includes several user-friendly features highlighted below.
- Simple Claim Input: Users can enter any recent piece of news or factual claim they want to verify.
- Result Summary: Provides a clear verdict with color-coding (green for true, red for false, gray for uncertain).
- Evidence Exploration: Tabbed interface to explore supporting and contradicting evidence.
- Source Citations: Clear attribution (with URLs) of all evidence sources.
- Processing Insights: Visibility into the reasoning process and processing time.
User Flow
The image below represents the AskVeracity web interface showing claim verification results.
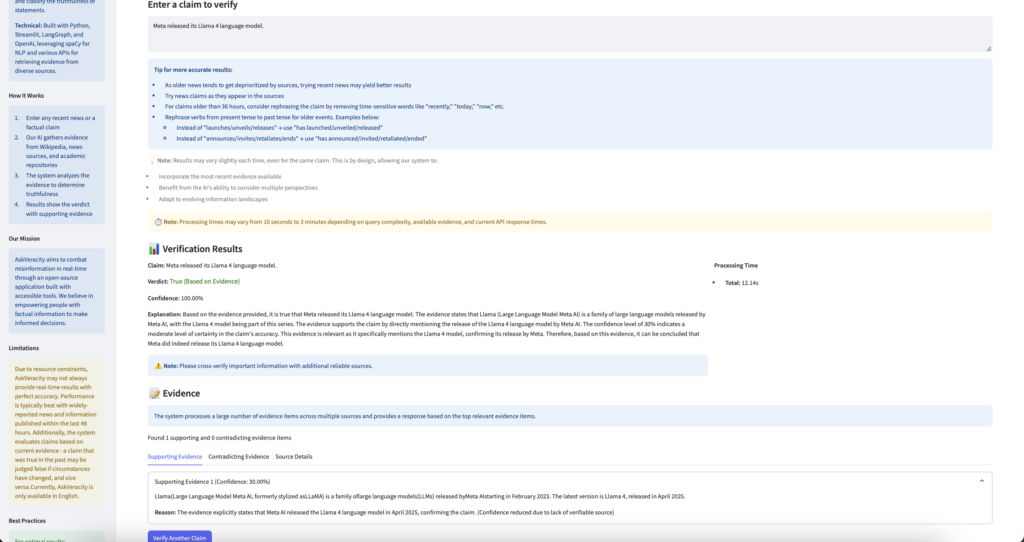
The user flow is designed to be straightforward and is given below.
- User enters a claim in the text area.
- User clicks the “Verify Claim” button.
- System displays a loading indicator with progress updates.
- Results appear with verdict, confidence score, and explanation.
- User can explore evidence through the tabbed interface.
- User can verify another claim with a single click.
User Guidance
The interface provides guidance to help users get the most accurate results. This guidance helps users phrase their claims in ways that maximize the system’s ability to find relevant evidence.
# Add information about claim formatting
st.info("""
**Tip for more accurate results:**
- As older news tends to get deprioritized by sources, trying recent news may yield better results
- Try news claims as they appear in the sources
- For claims older than 36 hours, consider rephrasing the claim by removing time-sensitive words like "recently," "today," "now," etc.
- Rephrase verbs from present tense to past tense for older events. Examples below:
- Instead of "launches/unveils/releases" → use "has launched/unveiled/released"
- Instead of "announces/invites/retaliates/ends" → use "has announced/invited/retaliated/ended"
""")Future Enhancements
Based on the performance evaluation and user feedback, several potential enhancements have been identified for future development and are noted below. However, the core focus would be on improving the accuracy and efficiency of the system.
- Enhanced visualization of evidence relevance: Provide visual representations of how evidence connects to specific parts of claims.
- Support for user feedback: Allow users to rate verification results and contribute to system improvement.
- Streamlined fact-checking using only relevant sources: Currently, the system queries all available evidence sources regardless of claim type, which can be inefficient. A future optimization would include more intelligent source selection to query only the most relevant sources based on claim category and context, reducing processing time and API usage while maintaining or improving accuracy.”
- Source weighting for improved result relevance: Implement credibility scoring for different sources.
- Improved verdict confidence for challenging/ambiguous claims: Enhance classification for complex, nuanced, or ambiguous claims.
- Expanded fact-checking sources: Integrate additional authoritative sources for more comprehensive evidence gathering.
- Improved handling of multilingual claims: Support verification of claims in languages other than English.
- Integration with additional academic databases: Expand scholarly evidence sources beyond OpenAlex.
- Custom source credibility configuration: Allow users to specify preferred evidence sources.
- Historical claim verification database: Build a repository of previously verified claims for faster processing.
- API endpoint for programmatic access: Enable integration with other applications.
Ethical Considerations
As an AI-powered fact-checking system, AskVeracity raises several important ethical considerations. More below.
Avoiding Bias
Fact-checking systems must strive for neutrality. AskVeracity addresses potential bias through:
- Source Diversity: Gathering evidence from multiple and diverse sources.
- Category-agnostic Design: No preferential treatment of any claim category.
- Evidence-based Verdicts: Basing conclusions strictly on available evidence, without assigning special weight to any particular item.
- Transparent Classification: Clearly explaining the reasoning behind verdicts.
Privacy and Data Security
AskVeracity prioritizes user privacy through the following.
- No Data Storage: User claims are not stored persistently.
- Session-based Processing: Results are maintained only during the current session.
- Transparent API Usage: Clear information about data handling practices are available on the UI.
Limitations and Transparency
The system is transparent about its limitations. More below.
- Acknowledging Uncertainty: Clearly identifies cases with insufficient evidence.
- Confidence Indication: Provides confidence scores for all verdicts.
- Evidence Access: Gives users access to the same evidence used for verification.
- Processing Insights: Shares the reasoning process behind conclusions.
Responsibility in Information Dissemination
AskVeracity recognizes its responsibility in combating misinformation through the following.
- Safety-First Approach: Prioritizes the prevention of false assertions and enhances system reliability.
- Cross-verification Encouragement: Recommends additional verification for important information.
- Educational Component: Helps users understand how to evaluate factual claims.
Conclusion
The development of AskVeracity was motivated by the sole intention of thwarting the spread of misinformation and the belief that accessible fact-checking tools can empower individuals to make more informed decisions in an increasingly complex information landscape.
AskVeracity represents a step forward in automated fact-checking and misinformation detection. By combining an agentic AI approach with multi-source evidence retrieval and transparent classification, the system offers a practical tool for verifying factual claims in real-time.
The performance evaluation demonstrates that while the system is not perfect (with accuracy ranging from 50-57.5%), it achieves a high safety rate (82.5-85%), indicating its reliability, resilience, and effectiveness at avoiding the spread of misinformation. The system performs particularly well with true claims (68.4-73.7% accuracy) and takes a cautious approach with false claims, often classifying them as Uncertain rather than making incorrect assertions.
The key innovations in AskVeracity include:
- Category-aware Evidence Retrieval: Prioritizing sources based on claim type.
- Entity and Verb Matching: Ensuring relevance of retrieved evidence.
- Safety-first Classification: Avoiding false assertions when evidence is insufficient.
- Transparent Explanations: Providing clear reasoning behind verdicts.
The aforementioned innovations address common challenges in automated fact-checking, such as evidence availability, temporal sensitivity, and classification accuracy.
As misinformation continues to pose challenges to society, systems like AskVeracity can serve as valuable tools for individuals seeking to verify information. While no automated system can replace critical thinking and comprehensive fact-checking by professionals, AskVeracity demonstrates the potential of AI to assist in combating misinformation at scale. We intend to keep improving the system and encourage user feedback.
AskVeracity is available as an open-source application deployed on Hugging Face Spaces. The source code is available on GitHub under the MIT license.
Thank you for reading through! I genuinely hope you found the content useful. Feel free to reach out to us at ankanatwork@gmail.com and share your feedback and thoughts to help us make it better for you next time.
Acronyms used in the blog that have not been defined earlier: (a) Machine Learning (ML), (b) Artificial Intelligence (AI), (c) Really Simple Syndication (RSS), (d) Application Programming Interface (API), (e) Central Processing Unit (CPU), (f) virtual CPU (vCPU), (g) Random Access Memory (RAM), (h) SPARQL Protocol and RDF Query Language (SPARQL), and (i) Uniform Resource Locator (URL).