
ML and AI Blogs | Issue# 15 [April 05, 2025]
In this blog post, we will go through the architecture, design decisions, implementation, and other considerations of Anveshak: Spirituality Q&A (Anveshak means “seeker” in Sanskrit), a Retrieval-Augmented Generation (RAG) application. The application serves as a bridge between ancient Indian spiritual wisdom and modern technology, allowing users to ask questions and receive concise answers grounded in traditional spiritual texts.
Project Overview
Anveshak: Spirituality Q&A is an AI-powered Q&A system that provides answers to spiritual questions by referencing a curated collection of spiritual texts, philosophical treatises, and teachings from revered Saints, Sages, and Spiritual Masters of all backgrounds (primarily from India, but including other traditions).
It has been observed that all of the necessary knowledge for spiritual progress is available in Indian spiritual texts. Additionally, great Saints, Sages, Siddhas, Yogis, Sadhus, Rishis, Gurus, Mystics, and Spiritual Masters of all genders, backgrounds, traditions, and walks of life have imparted spiritual wisdom, knowledge, and guidance to beings for ages in the Indian subcontinent and beyond.
Our goal is to make a small contribution to the journey of beings toward self-discovery by making this knowledge available and accessible within ethical, moral, and resource-based constraints. We have no commercial or for-profit interests; this application is purely for educational purposes.
Additionally, through this humble effort, we offer our tribute, love, and gratitude to the higher beings – the Saints, Sages, and Masters – whose works, teachings, and wisdom have guided humanity and have inspired and informed this application.
The system combines the power of modern AI with the timeless wisdom found in these spiritual texts, making spiritual knowledge more accessible to seekers through concise, focused answers that honor the original sources.
Key Features
- Question-answering: Users can ask spiritual questions and receive concise answers grounded in traditional texts. The app provides a set of default questions one can try.
- Source Citations: All of the answers include references to the original texts.
- Configurable Retrieval: Users can adjust the number of sources and word limit for answers.
- Responsive Interface: Built with Streamlit for a clean and accessible experience.
- Privacy-focused: No user data or queries are saved.
- Concise Responses: Focused on providing short, direct answers, rather than lengthy explanations.
Architecture Overview of Anveshak: Spirituality Q&A
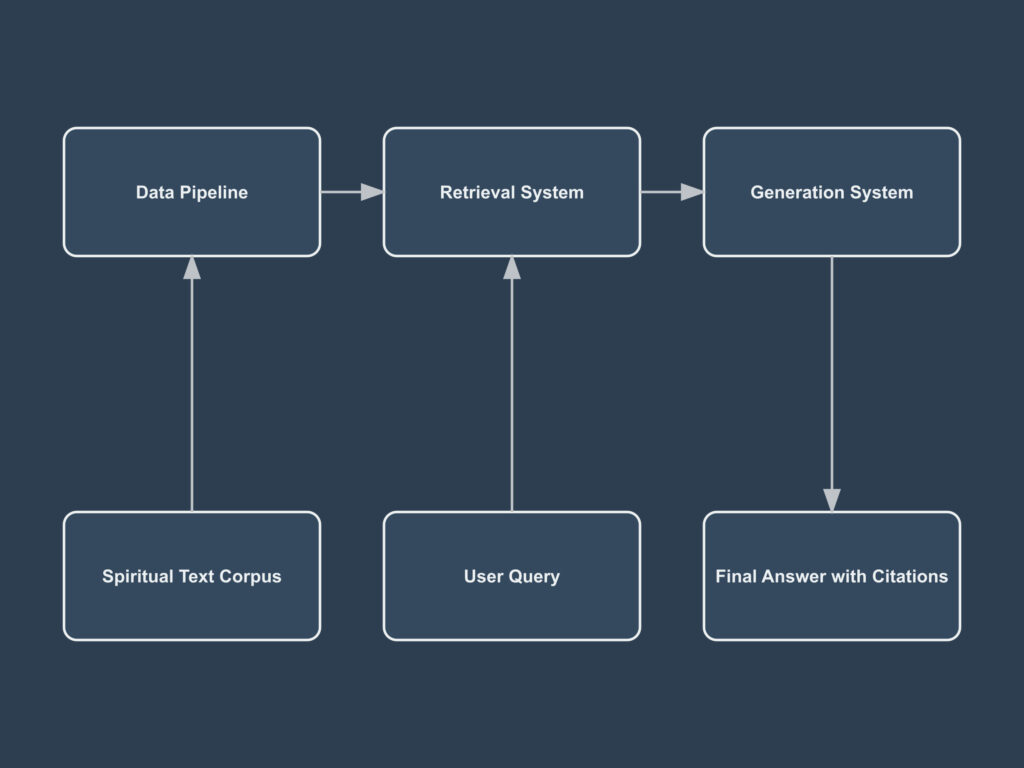
Anveshak follows a classic RAG architecture, consisting of three main components shown below.
- Data Processing Pipeline: Collects, cleans, and processes spiritual texts
- Retrieval System: Finds relevant passages from the text collection based on user queries
- Generation System: Synthesizes concise answers from retrieved passages
The figure below describes the architecture of Anveshak. See the architecture document for more.
Technical Stack
Anveshak is built using the following technologies.
- Front-end: Streamlit.
- Backend Processing: Python.
- Embedding Model: E5-large-v2.
- Vector Database: FAISS (denotes Facebook AI Similarity Search).
- Large Language Model (LLM): OpenAI GPT-3.5 Turbo.
- Storage: Google Cloud Storage (GCS).
- Deployment: Hugging Face Spaces (Free tier; CPU basic; 2 vCPUs with 16GB RAM).
The system implements robust authentication handling for cloud services Google Cloud Platform or GCP) to securely manage API access and data retrieval across different deployment environments. See utils.py for more.
The Data Pipeline
The data pipeline is the foundation of the system. It processes a collection of approximately 133 digitized spiritual texts sourced from the public domain.
Data Collection
The system utilizes texts from various traditions, and includes the following.
- Ancient Sacred Indian Texts: The Vedas, Upanishads, Puranas, Sutras, Dharmaśāstras, and Agamas.
- Classical India Texts: The Bhagavad Gita, The Śrīmad Bhāgavatam, and others.
- Indian Historical Texts: The Mahabharata and The Ramayana.
- Teachings of Revered Indian Saints and Siddhas: Includes Śrī Caitanya, Sri Ramakrishna, Swami Vivekananda, Sri Ramana Maharshi, Sri Nisargadatta Maharaj, Paramhansa Yogananda, Swami Sri Yukteswar Giri, Shri Lahiri Mahashaya, Sri Aurobindo, Sri Sri Ma Anandamayi, His Divine Grace A.C. Bhaktivedanta Swami Prabhupāda, Baba Neeb Karori (Neem Karoli Baba), Baba Lokenath, Shri Sai Baba, Bhagawan Nityananda, Swami Muktananda, Swami Sivananda, and many others. Teachings from various other traiditions have also been included. See list here.
- Works from Various Spiritual Traditions: Includes Advaita Vedanta, Bhakti, Yoga, Patanjali, Shakti and Shaktha, Tantra, and South Indian Vaishnavism and more.
All texts were ethically sourced from freely available resources like archive.org, with full acknowledgment of the original publishers. See thank you note and footer note, sources and attribution note, and publishers for more.
Additionally, a structured metadata.jsonl was created and used to enrich the retrieval process, where each JSON entry contains key bibliographic information about a text, such as title, author, publisher, uploaded status indicating whether the text was uploaded, and the source URL if available. This metadata provides essential context for properly attributing spiritual texts in user responses.
Note: No direct information about the spiritual texts used to support this work is being shared publicly. The books, names, and publishers only come up with the citations accompanying answers to user queries.
Text Processing Pipeline
While the majority of the texts were already publicly available in the text format, others were freely available PDF files that were downloaded and converted to text. The text processing was done using a Colab L4 GPU. The publicly available text files were downloaded, while the text files converted from PDF files were uploaded from the local environment to the Colab environment. These comprise the raw texts used for training.
The raw texts were uploaded and stored in GCS and processed further. The text processing pipeline is shown below. See preprocessing.ipynb for the complete preprocessing functionality.
Raw Texts → Cleaning → Chunking → Embedding → Indexing → GCS StorageLet us look at the text processing function (see preprocessing.ipynb).
def rigorous_clean_text(text):
"""
Clean text by removing metadata, junk text, and formatting issues.
This function:
1. Removes HTML tags using BeautifulSoup
2. Removes URLs and standalone numbers
3. Removes all-caps OCR noise words
4. Deduplicates adjacent identical lines
5. Normalizes Unicode characters
6. Standardizes whitespace and newlines
Args:
text (str): The raw text to clean
Returns:
str: The cleaned text
"""
text = BeautifulSoup(text, "html.parser").get_text()
text = re.sub(r"https?:\/\/\S+", "", text) # Remove links
text = re.sub(r"\b\d+\b", "", text) # Remove standalone numbers
text = re.sub(r"\b[A-Z]{5,}\b", "", text) # Remove all-caps OCR noise words
lines = text.split("\n")
cleaned_lines = []
last_line = None
for line in lines:
line = line.strip()
if line and line != last_line:
cleaned_lines.append(line)
last_line = line
text = "\n".join(cleaned_lines)
text = unicodedata.normalize("NFKD", text)
text = re.sub(r"\s+", " ", text).strip()
text = re.sub(r"\n{2,}", "\n", text)
return textThe cleaning process removes HTML tags using BeautifulSoup, eliminates URLs and standalone numbers, removes all-caps OCR noise words, deduplicates adjacent identical lines, normalizes Unicode characters, and standardizes whitespace and newlines to ensure high-quality text for embedding.
Text Chunking and Embedding
The cleaned texts are split into smaller chunks of approximately 500 words with a 50-word overlap to maintain context across chunks. Each chunk is then embedded using the E5-large-v2 model, which converts text into high-dimensional vectors that capture semantic meaning. The text chunking process is shown below (see preprocessing.ipynb).
def chunk_text(text, chunk_size=500, overlap=50):
"""
Split text into smaller, overlapping chunks for better retrieval.
Args:
text (str): The text to chunk
chunk_size (int): Maximum number of words per chunk
overlap (int): Number of words to overlap between chunks
Returns:
list: List of text chunks
"""
words = text.split()
chunks = []
i = 0
while i < len(words):
chunk = " ".join(words[i:i + chunk_size])
chunks.append(chunk)
i += chunk_size - overlap
return chunksFor embedding generation, we use the E5-large-v2 model, which is particularly well-suited for retrieval tasks.
def create_embeddings(text_chunks, batch_size=32):
"""
Generate embeddings for the given chunks of text using the specified embedding model.
This function:
1. Uses SentenceTransformer to load the embedding model
2. Prefixes each chunk with "passage:" as required by the E5 model
3. Processes chunks in batches to manage memory usage
4. Normalizes embeddings for cosine similarity search
Args:
text_chunks (list): List of text chunks to embed
batch_size (int): Number of chunks to process at once
Returns:
numpy.ndarray: Matrix of embeddings, one per text chunk
"""
# Load the model with GPU optimization
model = SentenceTransformer(EMBEDDING_MODEL)
device = "cuda" if torch.cuda.is_available() else "cpu"
model = model.to(device)
print(f"🚀 Using device for embeddings: {device}")
prefixed_chunks = [f"passage: {text}" for text in text_chunks]
all_embeddings = []
for i in range(0, len(prefixed_chunks), batch_size):
batch = prefixed_chunks[i:i+batch_size]
# Move batch to GPU (if available) for faster processing
with torch.no_grad():
batch_embeddings = model.encode(batch, convert_to_numpy=True, normalize_embeddings=True)
all_embeddings.append(batch_embeddings)
if (i + batch_size) % 100 == 0 or (i + batch_size) >= len(prefixed_chunks):
print(f"📌 Processed {i + min(batch_size, len(prefixed_chunks) - i)}/{len(prefixed_chunks)} documents")
return np.vstack(all_embeddings).astype("float32")The embedding model transforms each text chunk into a 1024-dimensional vector, capturing the semantic meaning and enabling similarity-based retrieval. See preprocessing.ipynb for more.
Vector Storage with FAISS
The embeddings are stored in a FAISS index, which enables efficient similarity search. FAISS is particularly useful for this application because it:
- Provides fast similarity search even with a large number of vectors.
- Supports inner product (cosine similarity) search, which is ideal for embeddings.
- Has a small memory footprint compared to other vector databases.
# Build FAISS index
dimension = all_embeddings.shape[1]
index = faiss.IndexFlatIP(dimension)
index.add(all_embeddings)See preprocessing.ipynb for more.
The Retrieval System
When a user asks a question, the retrieval system:
- Embeds the query using the E5-large-v2 model.
- Performs a similarity search in the FAISS index.
- Retrieves the most relevant text chunks.
- Appends metadata (source, author, publisher) to each chunk.
The retrieval process for the most relevant passages is shown below. Find the complete code for the retrieval engine in rag_engine.py.
def retrieve_passages(query, faiss_index, text_chunks, metadata_dict, top_k=5, similarity_threshold=0.5):
"""
Retrieve the most relevant passages for a given spiritual query.
This function:
1. Embeds the user query using the same model used for text chunks
2. Finds similar passages using the FAISS index with cosine similarity
3. Filters results based on similarity threshold to ensure relevance
4. Enriches results with metadata (title, author, publisher)
5. Ensures passage diversity by including only one passage per source title
Args:
query (str): The user's spiritual question
faiss_index: FAISS index containing passage embeddings
text_chunks (dict): Dictionary mapping IDs to text chunks and metadata
metadata_dict (dict): Dictionary containing publication information
top_k (int): Maximum number of passages to retrieve
similarity_threshold (float): Minimum similarity score (0.0-1.0) for retrieved passages
Returns:
tuple: (retrieved_passages, retrieved_sources) containing the text and source information
"""
try:
print(f"\n🔍 Retrieving passages for query: {query}")
query_embedding = get_embedding(query)
distances, indices = faiss_index.search(query_embedding, top_k * 2)
print(f"Found {len(distances[0])} potential matches")
retrieved_passages = []
retrieved_sources = []
cited_titles = set()
for dist, idx in zip(distances[0], indices[0]):
print(f"Distance: {dist:.4f}, Index: {idx}")
if idx in text_chunks and dist >= similarity_threshold:
title_with_txt, author, text = text_chunks[idx]
clean_title = title_with_txt.replace(".txt", "") if title_with_txt.endswith(".txt") else title_with_txt
clean_title = unicodedata.normalize("NFC", clean_title)
if clean_title in cited_titles:
continue
metadata_entry = metadata_dict.get(clean_title, {})
author = metadata_entry.get("Author", "Unknown")
publisher = metadata_entry.get("Publisher", "Unknown")
cited_titles.add(clean_title)
retrieved_passages.append(text)
retrieved_sources.append((clean_title, author, publisher))
if len(retrieved_passages) == top_k:
break
print(f"Retrieved {len(retrieved_passages)} passages")
return retrieved_passages, retrieved_sources
except Exception as e:
print(f"❌ Error in retrieve_passages: {str(e)}")
return [], []Understanding Similarity Threshold
A key aspect of the retrieval system is the similarity threshold. By setting a threshold of 0.5, we ensure that only passages with significant relevance to the query are retrieved. This helps filter out noise and provides more accurate answers.
The Generation System
The generation system takes the retrieved passages and synthesizes a coherent answer using a LLM. The LLM is guided by:
- A carefully crafted system prompt that emphasizes spiritual guidance.
- The query context, including the relevant passages with their sources.
- Word limit constraints to keep answers concise.
The following function implements this answer generation process, translating these guiding principles into code. See rag_engine.py for code.
def answer_with_llm(query, openai_client, context=None, word_limit=200):
"""
Generate an answer using the OpenAI GPT model with formatted citations.
This function:
1. Formats retrieved passages with source information
2. Creates a prompt with system and user messages
3. Calls the OpenAI API to generate an answer
4. Trims the response to the specified word limit
The system prompt ensures answers maintain appropriate respect for spiritual traditions,
synthesize rather than quote directly, and acknowledge gaps when relevant information
isn't available.
Args:
query (str): The user's spiritual question
openai_client (OpenAI): Configured OpenAI client instance
context (list, optional): List of (source_info, text) tuples for context
word_limit (int): Maximum word count for the generated answer
Returns:
str: The generated answer or an error message
"""
try:
if context:
formatted_contexts = []
total_chars = 0
max_context_chars = 4000 # Limit context size to avoid exceeding token limits
for (title, author, publisher), text in context:
remaining_space = max(0, max_context_chars - total_chars)
excerpt_len = min(150, remaining_space)
if excerpt_len > 50:
excerpt = text[:excerpt_len].strip() + "..." if len(text) > excerpt_len else text
formatted_context = f"[{title} by {author}, Published by {publisher}] {excerpt}"
formatted_contexts.append(formatted_context)
total_chars += len(formatted_context)
if total_chars >= max_context_chars:
break
formatted_context = "\n".join(formatted_contexts)
else:
formatted_context = "No relevant information available."
system_message = (
"You are an AI specialized in spirituality, primarily based on Indian spiritual texts and teachings."
"While your knowledge is predominantly from Indian spiritual traditions, you also have limited familiarity with spiritual concepts from other global traditions."
"Answer based on context, summarizing ideas rather than quoting verbatim."
"If no relevant information is found in the provided context, politely inform the user that this specific query may not be covered in the available spiritual texts. Suggest they try a related question or rephrase their query or try a different query."
"Avoid repetition and irrelevant details."
"Ensure proper citation and do not include direct excerpts."
"Maintain appropriate, respectful language at all times."
"Do not use profanity, expletives, obscenities, slurs, hate speech, sexually explicit content, or language promoting violence."
"As a spiritual guidance system, ensure all responses reflect dignity, peace, love, and compassion consistent with spiritual traditions."
"Provide concise, focused answers without lists or lengthy explanations."
)
user_message = f"""
Context:
{formatted_context}
Question:
{query}
"""
try:
llm_model = st.secrets["LLM_MODEL"]
except KeyError:
print("❌ Error: LLM model not found in secrets")
return "I apologize, but I am unable to answer at the moment."
response = openai_client.chat.completions.create(
model=llm_model,
messages=[
{"role": "system", "content": system_message},
{"role": "user", "content": user_message}
],
max_tokens=200,
temperature=0.7
)
# Extract the answer and apply word limit
answer = response.choices[0].message.content.strip()
words = answer.split()
if len(words) > word_limit:
answer = " ".join(words[:word_limit])
if not answer.endswith((".", "!", "?")):
answer += "."
return answer
except Exception as e:
print(f"❌ LLM API error: {str(e)}")
return "I apologize, but I am unable to answer at the moment."The prompt engineering ensures that the LLM:
- Maintains respect for spiritual traditions.
- Synthesizes rather than quotes directly.
- Acknowledges gaps in knowledge when relevant information is not available.
- Keeps answers focused and concise.
The Query Processing Pipeline
While we have explored the individual components of our RAG system, it is important to understand how they come together to answer a user’s spiritual question. At the heart of Anveshak: Spirituality Q&A’s question-answering capability is the process_query() function, which internally calls cached_process_query(). This function serves as the central orchestrator, seamlessly integrating embedding-based retrieval and language model generation to deliver spiritual knowledge from traditional texts in an accessible format. It manages the entire flow, from the initial query to the final, cited response, ensuring a cohesive and efficient pipeline.
@st.cache_data(ttl=3600, show_spinner=False)
def cached_process_query(query, top_k=5, word_limit=200):
"""
Process a user query with caching to avoid redundant computation.
This function is cached with a Time-To-Live (TTL) of 1 hour, meaning identical
queries within this time period will return cached results rather than
reprocessing, improving responsiveness.
Args:
query (str): The user's spiritual question
top_k (int): Number of sources to retrieve and use for answer generation
word_limit (int): Maximum word count for the generated answer
Returns:
dict: Dictionary containing the query, answer, and citations
"""
print(f"\n🔍 Processing query (cached): {query}")
# Load all necessary data resources (with caching)
faiss_index, text_chunks, metadata_dict, openai_client = cached_load_data_files()
# Handle missing data gracefully
if faiss_index is None or text_chunks is None or metadata_dict is None or openai_client is None:
return {
"query": query,
"answer_with_rag": "⚠️ System error: Data files not loaded properly.",
"citations": "No citations available."
}
# Step 1: Retrieve relevant passages using similarity search
retrieved_context, retrieved_sources = retrieve_passages(
query,
faiss_index,
text_chunks,
metadata_dict,
top_k=top_k
)
# Step 2: Format citations for display
sources = format_citations(retrieved_sources) if retrieved_sources else "No citation available."
# Step 3: Generate the answer if relevant context was found
if retrieved_context:
context_with_sources = list(zip(retrieved_sources, retrieved_context))
llm_answer_with_rag = answer_with_llm(query, openai_client, context_with_sources, word_limit=word_limit)
else:
llm_answer_with_rag = "⚠️ No relevant context found."
# Return the complete response package
return {"query": query, "answer_with_rag": llm_answer_with_rag, "citations": sources}
def process_query(query, top_k=5, word_limit=200):
"""
Process a query through the RAG pipeline with proper formatting.
This is the main entry point for query processing, wrapping the cached
query processing function.
Args:
query (str): The user's spiritual question
top_k (int): Number of sources to retrieve and use for answer generation
word_limit (int): Maximum word count for the generated answer
Returns:
dict: Dictionary containing the query, answer, and citations
"""
return cached_process_query(query, top_k, word_limit)This orchestration function makes several important design decisions.
- Graceful Error Handling: If the data files are not properly loaded, it returns a user-friendly error message rather than crashing.
- Configuration Flexibility: Users can adjust the number of sources (
top_k) and word limit for their answers. - Complete Packaging: Returns a dictionary with the original query, generated answer, and formatted citations.
- Performance Optimization: Implements caching to avoid redundant processing of identical questions. See section Performance Optimization for more on the caching strategies used in this work.
The process_query() function represents the culmination of the RAG architecture, bringing together embedding-based retrieval and language model generation into a cohesive system that delivers spiritual knowledge from traditional texts in an accessible format.
User Interface Design
The User Interface (UI) is built with Streamlit, offering a clean, intuitive experience. The key components are:
- Question Input: A text field where users enter their spiritual questions
- Customization Controls: Sliders to adjust the number of sources and word limit
- Pre-selected Questions: Common spiritual questions users can click on
- Answer Display: Shows the answer along with source citations
- Acknowledgment Section: Recognizes the sources of spiritual wisdom
Below is a simplified version of the Streamlit UI code, showing selected parts of app.py. For complete UI code and functionality, see app, sources, publishers, and the contact page.
...
# Custom HTML/JS for title styling
st.markdown('<div class="main-title">Anveshak</div>', unsafe_allow_html=True)
st.markdown('<div class="subtitle">Spirituality Q&A</div>', unsafe_allow_html=True)
...
# Create a form with a dynamic key (to allow resetting after submission)
with st.form(key=f"query_form_{st.session_state.form_key}"):
query = st.text_input("Ask your question:", key="query_input",
placeholder="Press enter to submit your question", disabled=st.session_state.is_processing)
submit_button = st.form_submit_button("Get Answer", on_click=handle_form_submit, disabled=st.session_state.is_processing)
...
# Sliders for customization - allows users to control retrieval parameters
col1, col2 = st.columns(2)
with col1:
# Control how many different sources will be used for the answer
top_k = st.slider("Number of sources:", 3, 10, 5)
with col2:
# Control the maximum length of the generated answer
word_limit = st.slider("Word limit:", 50, 500, 200)
...
# Process the query only if it has been explicitly submitted
# This prevents automatic processing on page load or slider adjustments
if st.session_state.submit_clicked and st.session_state.last_query:
st.session_state.submit_clicked = False
with st.spinner("Processing your question..."):
try:
# Call the RAG engine with the user's question and retrieval parameters
result = process_query(st.session_state.last_query, top_k=top_k, word_limit=word_limit)
st.session_state.last_answer = result # Store result in session state
except Exception as e:
st.session_state.last_answer = {"answer_with_rag": f"Error processing query: {str(e)}", "citations": ""}
# Display the answer and citations if available
st.subheader("Answer:")
st.write(result["answer_with_rag"])
st.subheader("Sources:")
for citation in result["citations"].split("\n"):
st.write(citation)
...Performance Optimization
Several optimization techniques were implemented to ensure a responsive user experience. More below.
Caching Strategies
Streamlit’s caching decorators were used extensively to avoid redundant computations.
@st.cache_resourcecaches resource-intensive objects that remain constant.- The embedding model (E5-large-v2) is loaded and cached once per session.
- The FAISS index, text chunks, and metadata files are downloaded and loaded only once.
@st.cache_datawith a TTL of 1 hour caches processed query results, preventing identical questions from being reprocessed within that timeframe.
# ...
@st.cache_resource(show_spinner=False)
def cached_load_model():
# Load embedding model once and cache it
# ...
@st.cache_resource(show_spinner=False)
def cached_load_data_files():
# Load FAISS index, text chunks, metadata, and OpenAI client once and cache them
# ...
@st.cache_data(ttl=3600, show_spinner=False)
def cached_process_query(query, top_k=5, word_limit=200):
# Cache query results for an hour
# ...For complete code, see rag_engine.py.
Resource Management
Note that this work uses the basic, free deployment tier of Hugging Face Spaces with 16GB of RAM. To avoid memory issues, especially with the large embedding model, several techniques were implemented.
- Force CPU usage for Embedding Model: This ensures consistent performance on CPU-only environments like Hugging Face Spaces, avoiding potential memory issues when working with large embedding models.
- Garbage Collection: After generating embeddings, unused objects are explicitly deleted and garbage collection is triggered.
- Batch Processing: Embeddings are generated in batches to manage memory usage.
Here is a snippet of the optimizations code below. See rag_engine.py for more.
# ...
# Force model to CPU for stability
os.environ["CUDA_VISIBLE_DEVICES"] = ""
# ...
# Memory management after embedding generation
del outputs, inputs
gc.collect()
# ...Ethical Considerations
Several ethical considerations guided the development of Anveshak: Spirituality Q&A.
Copyright and Attribution
While we have not obtained explicit copyright permissions, all of the texts in the system come from freely available sources in the public domain, and we have taken extensive measures to respect intellectual property by crediting the authors and publishers throughout the application. Anveshak:
- Includes comprehensive author and publisher acknowledgments.
- Implements word limits to prevent excessive content reproduction.
- Avoids direct citations and re-presents findings instead.
- Cites sources for all answers.
- Encourages users to purchase original texts from publishers.
See thank you note and footer note, sources and attribution note, and publishers.
Respecting Spiritual Traditions
Anveshak is designed to:
- Present spiritual knowledge with appropriate reverence.
- Acknowledge the works of Saints, Sages, Siddhas, Yogis, Sadhus, Rishis, Gurus, Mystics, and Spiritual Masters of all genders, backgrounds, traditions, and walks of life.
- Avoid claims of definitive interpretation.
- Acknowledge the limitations of AI in spiritual matters.
- Focus on educational purposes rather than replacing spiritual guidance.
See Sources to learn about the different spiritual traditions that enrich Anveshak.
User Privacy
Anveshak does not save or store any user data or queries, respecting the private nature of spiritual inquiry.
Limitations and Considerations
While Anveshak: Spirituality Q&A represents an exciting bridge between spirtutal wisdom and modern technology, we acknowledge several important limitations.
Technical Constraints: Anveshak is not a general conversational AI but a specialized tool for spiritual questions. It provides concise, focused answers rather than lengthy explanations or narratives, and may return slightly different responses to the same question as it draws from diverse spiritual traditions.
AI-Generated Content: Responses are synthesized by AI based on retrieved texts. While we strive for accuracy, AI interpretation may not perfectly capture the nuanced meaning, context, or intent of original spiritual teachings.
Data Privacy: Though we do not save user queries or personal data, interactions with Anveshak are processed using OpenAI’s services and are subject to their privacy policies and data handling practices.
Proper Attribution: The inclusion of any spiritual teacher, text, or tradition does not imply their endorsement of this application. We reference these sources with deep respect but claim no official affiliation.
Supplementary Tool: Anveshak is designed to complement, not replace, traditional spiritual learning methods. We strongly encourage seekers to pursue deeper understanding through experienced spiritual guides, direct practice, and studying original texts in their complete form.
Language Limitation: Currently, Anveshak is only available in English, limiting accessibility for non-English speakers.
We share these considerations in the spirit of transparency and to honor the profound traditions whose wisdom we aim to make more accessible.
Future Directions
Several enhancements could further improve Anveshak: Spirituality Q&A.
- Multi-language Support: Incorporate texts in Sanskrit, Hindi, Bengali, Tamil, and other Indian languages, with translation capabilities.
- Improved Passage Retrieval: Implement hybrid retrieval combining dense and sparse retrieval methods.
- Expanded Text Corpus: Include more commentaries and perspectives, both ancient and recent.
- User Feedback Integration: Allow users to rate answers and improve retrieval based on feedback.
- Open-source LLM Integration: Use open-source alternatives for the LLM. We explored several open-source language models for Anveshak, but faced challenges with model loading on resource-constrained platforms, response latency, and information accuracy. Despite these current limitations, the rapid pace of AI innovation gives us confidence that high-quality open-source alternatives will soon become viable for our system.
Conclusion
Anveshak: Spirituality Q&A demonstrates the potential of AI to make invaluable spiritual wisdom more accessible. By combining modern retrieval techniques with LLMs, we can create systems that help seekers navigate the vast ocean of spiritual literature.
The core philosophy guiding this project is that while technology can facilitate access to spiritual knowledge, the journey to self-discovery remains deeply personal. As Anveshak states:
The path and journey to the SELF is designed to be undertaken alone. The all-encompassing knowledge is internal and not external.
Anveshak serves not as a replacement for personal exploration or spiritual guidance, but as a humble tool to assist seekers in accessing the wisdom contained in traditional texts.
You can try Anveshak: Spirituality Q&A on Hugging Face Spaces or explore the code on GitHub (Apache 2.0 License).
Thank you for reading through! We genuinely hope you found the content useful. Feel free to reach out to us at ankanatwork@gmail.com and share your feedback and thoughts to help us make it better for you next time.
Acronyms used in the blog that have not been defined earlier: (a) Machine Learning (ML), (b) Artificial Intelligence (AI), (c) Question & Answer (Q&A), (d) Central Processing Unit (CPU), (e) virtual CPU (vCPU), (f) Random Access Memory (RAM), (g) Application Programming Interface (API), (h) Gigabyte (GB), (i) JavaScript Object Notation (JSON), (j) Uniform Resource Locator (URL), (k) Portable Document Format (PDF), (l) HyperText Markup Language (HTML), (m) Arguments (Args), (n) Optical Character Recognition (OCR), (o) Identity (ID), (p) Generative Pre-trained Transformer (GPT), and (q) Javascript (JS).